
今回はWIndowsで使えるサイト丸ごとをコピーしてローカルに保存する【HTTrack Website Copier】をご紹介します。
私は参考にしたいサイトの構造把握とか「サーバーに入れなくなったので、とりあえず何とかしたい」などの保存依頼時に、念の為使う事があります。
当然サイトを完全コピーしようとする為、情報量がかなり膨大になり参考にできる箇所が増えます。
本物のサイトを検証機能で確認しつつ、ローカルでファイル構造を見ると初心者は結構参考になったりするんですよね。
凄いツールがあるんだねぇ
WEBサイトの構成は表層だけでも
情報が沢山出てるからね
HTTrack Website Copierのダウンロード
WindowとLinaxで使えるソフト、HTTrack Website Copierをまずはダウンロードします。
まずはこちらのダウンロードサイトへ飛びます。
直接ダウンロードページのURLになっています。
このなかから適切な物をダウンロードします。
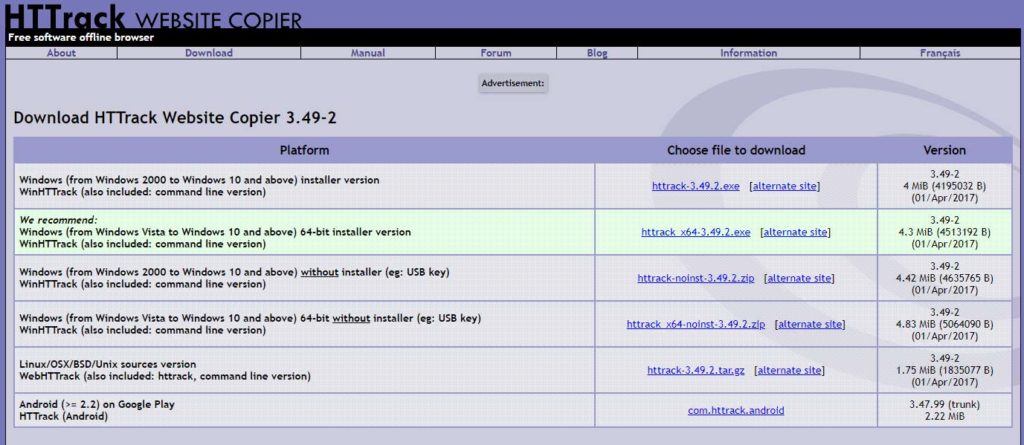
私の場合はWindowsの64bitである為、2番目の項目。
仮にWindowsの32bitを使っているなら1番目の項目をダウンロードします。

ダウンロードしたexeファイルを起動して、インストールウィザードにしたがってインストールしていきます。
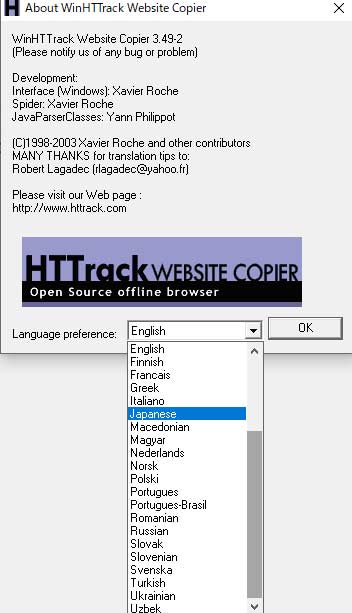
初回起動時には言語選択が開きますので、念のため日本語を設定しておきましょう。
サイトを保存する
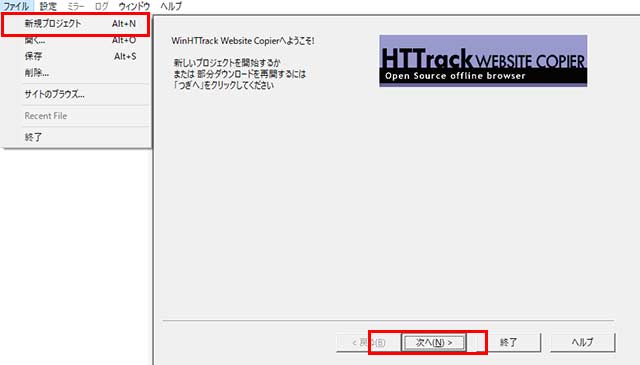
【ファイル】から【新規プロジェクト】を選択し【次へ】を選びます。
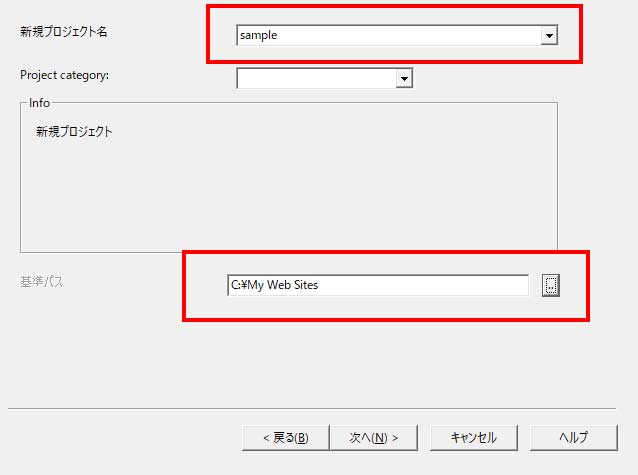
新規プロジェクト名と保存先を選択します。
新規プロジェクト名は取得先のサイト名などを付けておくとよいでしょう。
保存フォルダは任意の場所に変えてしまってよいです。
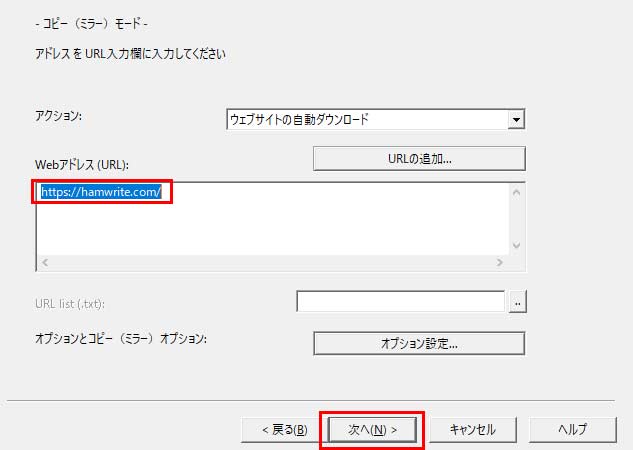
取得したいサイトのURLを記載して【次へ】を押します。
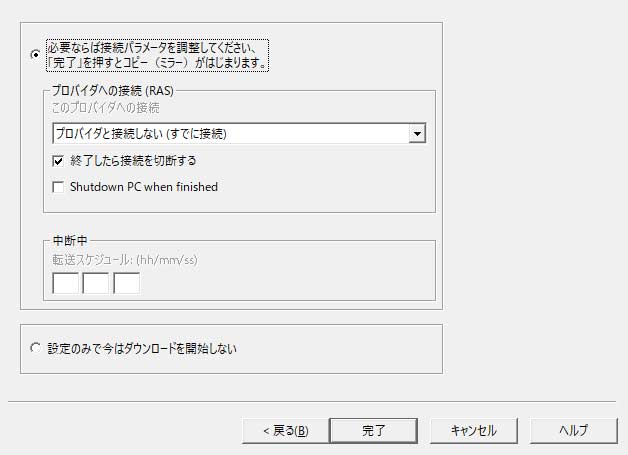
ここで【完了】を押すと取得を開始します。
数十分ほどかかる事もあるので、気長に待ちましょう。
取得作業完了
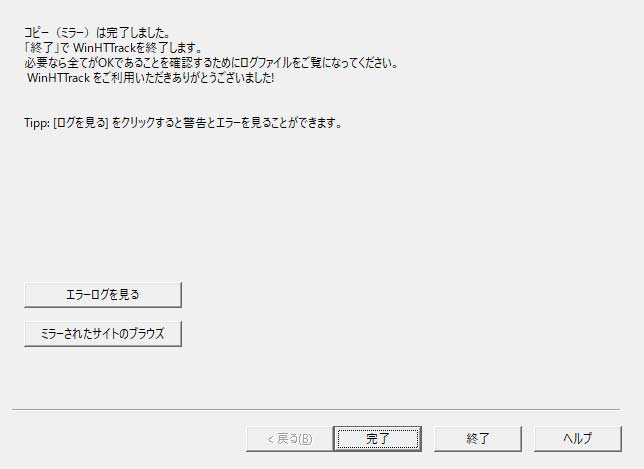
作業が完了するとこの様に、報告が来ます。
この画面でできることは特にないので、そのまま完了を押してください。

今回はデスクトップの【files】にコピーさせたのでこの様になっています。

ログ展開の為メモ帳が自動で開きます。
これは【×】を押して大丈夫です。

中身。プロジェクト名として記述した名前で保存されています。
ここの【index.html】を開くと中身が見れます。

開くとプロジェクト名が表示されているので、クリックすると閲覧可能です。
これはローカルのファイルを参照している為、ネットが切れていても読み込むことができます。
今回の確認はここまでです。お疲れ様でした。
使い道
HTTrack Website Copierの使い道としては、対象サイトの構造を知ったり。
元となっているhtmlソースを見ることで勉強につなげたりと基本的には学習用途と考えられます。
また、閉鎖が予告されているサイトを私的な目的で残すといった使い方ですね。
注意点としては、外部ツールを使って作ったページなどはやはり取得できていない事があるという事ですね。
完全なページ再現は外部からの情報だけでは不可能な場合があるっぽいので過信しすぎない事が重要。
当然、ページ数のあるサイトほど重くなるのですべてをというのは非常に危険です。
画像保存目的などではなく、構造勉強を基本とした参考にしたい何処かの公式サイトやLPなどの把握用途に止めるのが無難です。
また、製作者の意図の及ばないところでアップロードしてしまうのは法律に抵触する可能性があるので、あくまでローカル保存に留めておくように注意しましょう。
悪用厳禁!
用途と使用目的をしっかり把握して、ルールを守って使っていきましょう。


コメント